Maizeverse Crew: interacting naturally and directly with digital content.

Alessio Bosca
Senior specialist, natural language processing
Craft Meaningful Experiences
2022

Can the use of voice be integrated within a virtual environment to make interaction with its elements even more direct and natural?
Digital Environments
Metaverses and virtual environments are increasingly used to gain experience in the contemporary world, from entertainment and education to attending events and shopping. These capabilities are also innovating how we work, not only in cross-cutting and direct ways, such as virtual meetings and e-commerce, but also in the production of tangible objects that are not digital natives, such as furniture, shoes, and household appliances.
Digital environments and 3D modeling play a pivotal role in experimenting with these new approaches. However, the skills required for these activities involve unique languages and complex configurations that require a lengthy learning process and experience. This creates a barrier to entry for creative experimentation with these technologies.

The Rationale for the Research
We wondered if it would be possible to simplify the setup of a virtual reality environment by interacting with the system through voice commands and requests from within.
To explore this further, we created the Maizeverse Crew, combining a contemporary challenge — making sophisticated technologies accessible — with two of our specific skills: VR and linguistic analysis.
How can we make the 3D rendering process more accessible? How can we apply and simulate the language and interactions typical of a photo shoot within a digital context?
To achieve this, we created a digital photo assistant capable of collaborating with the user within a VR environment that replicates the experience of a photo shoot.
Two supporting tools/resources
Needless to say, we knew from the start that we had a part of the solution: our conversational AI platform, CELI.dialog. This tool enables the configuration of voice interactions.
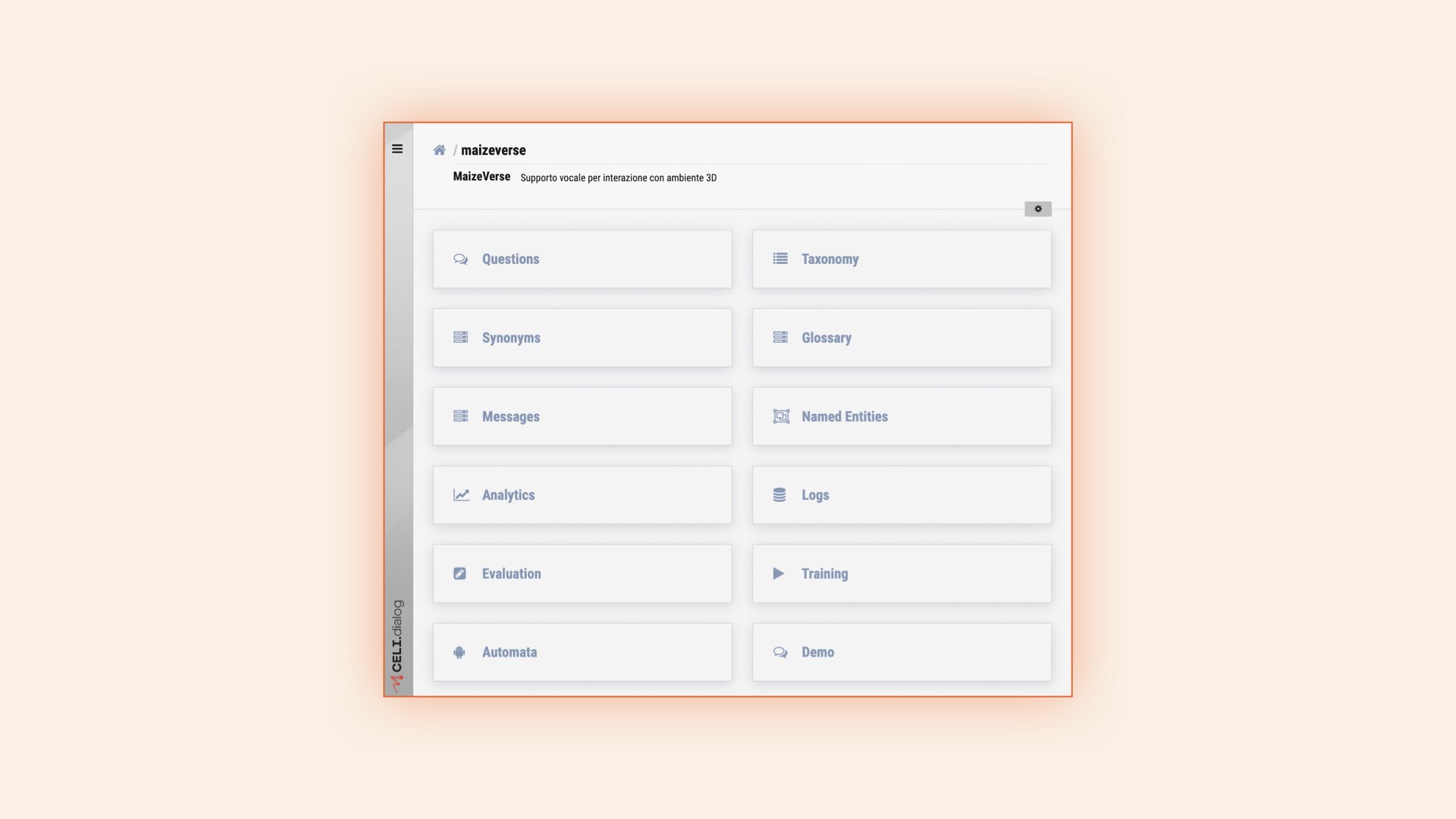
CELI.dialog Back Office
It includes several modules that leverage our proprietary technologies to create personalized conversational experiences:
- Natural Language Understanding: analyzes text and voice to extract meaning.
- Dialog Manager: manages dialog logic and guides the conversation.
- Natural Language Generation: generates text or voice response.
- Proprietary and customizable Back Office: creates and manages conversational assistants independently.
We added to this tool a VR environment that simulates a virtual photo studio where digital objects can be uploaded and controlled, including subjects to be photographed, backgrounds, and lights to optimally illuminate the scene.
So how did we integrate these two resources?
Phase 1: Defining the scope of the project
Through two phases, we succeeded in imagining and experimenting with how voice interaction could make using a VR environment easier and more effective.
The initial discussion and brainstorming session with our Service Design team resulted in some guidelines for defining behaviors and features of our digital assistant:
- Present the photo assistant with a clear digital avatar so that it can visually and instantly provide us with some information (I am active, I have understood the request, and I am thinking, etc.).
- Proactively guide the user through the initial setup of the photo studio and then assist with changes (to lights, backgrounds, object positions) and preparatory shots as needed.
- Exhibit intelligence in understanding the user’s abstract, high-level requests related to the desired objective and then translate them into actions and/or configurations in the VR environment.
- Leverage the richer informational context of the experience by combining voice interaction and location in the user’s VR environment (voice command + location and user’s point of view).

Space + Voice Context
Phase 2: Integrating the VR environment with CELI.dialog
In the second phase, we developed a module within the VR environment that could be activated by certain contextual conditions or by a wake-up word (“Hey Maize…”) and that could capture the user’s voice request.
The behavior of the digital agent was designed and configured through the CELI.dialog back office, allowing us to define the different intents, requests, or questions that our photo assistant should be able to handle and the corresponding responses or actions.
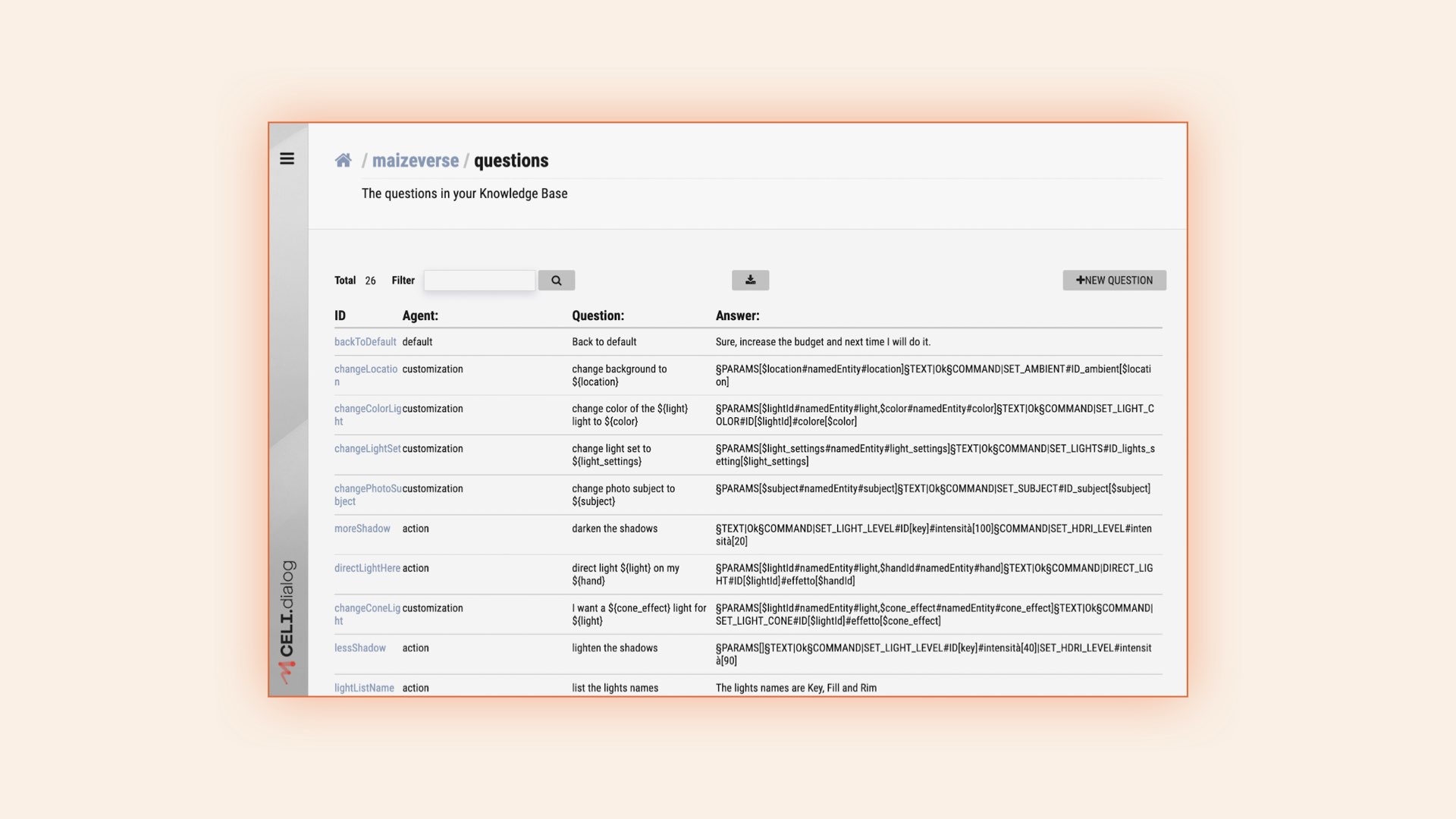
CELI.dialog Back Office — Configuration of Questions and Answers
Phase 3: The important thing is not to fall off the stage
The final phase of the development of our prototype consisted of a test: wearing a visor and trying out the interaction with the digital assistant in our VR lab. The goal of the interaction is to choose a subject among those available, configure the background and lights, choose a shot, and generate the desired render by taking a picture.
An excerpt of these interactions is shown in the video below.
Conclusions
As the Maizeverse Crew, we explored the possibility of integrating CELI.dialog into our VR projects. By taking advantage of the broader information context available in the digital environment and combining physical and verbal communication, we created a tool capable of translating complex requests into sequences of commands and possible actions.
During the review phase of the project, we identified several potential use cases that we hope will serve as a starting point for the implementation of innovative projects.

Thanks to the Maizeverse Crew: Raffaella Ventaglio, Chiara Albano, Alessio Bosca, Nazareno De Francesco, Luca Gaverina, Francesca Pizzutilo, and Marco Zoffoli with the precious support of Antonio Mazzei.